
Today I ran into a rather shocking situation while debugging some query relevancy issues in Watson Explorer AppBuilder. Another IBM Watson developer and I noticed that some results with a higher amount of matching terms in them were being ranked lower than some documents with fewer matches. This appears to be the opposite of what one would expect a search engine to do. These documents are not webpages so the WEX link analysis score doesn’t come into play here. Also, the contents were all weighted the same, 1, so there was nothing weird going on there.
This issue also made it painfully obvious that there are no good query debugging tools built into AppBuilder (come on IBM). The only way to debug this query was to head over the Watson Explorer engine and perform the same search against the same collection.
To demonstrate the issue I create 4 files on my local WEX development environment. All of the files just contain the words “Watson Explorer” multiple times, each on a separate line. Like this:
watson explorer
watson explorer
watson explorer
watson explorer
watson explorer
watson explorer
watson explorer
watson explorer
It made 4 files: 11.txt, 20.txt, 40.txt, and 8.txt. Each name refers to the number of times “Watson Explorer” is repeated. Then I executed a query, “Watson Explorer”, against the collection. You would expect them to be ranked from highest to lowest but take a look at what you get.
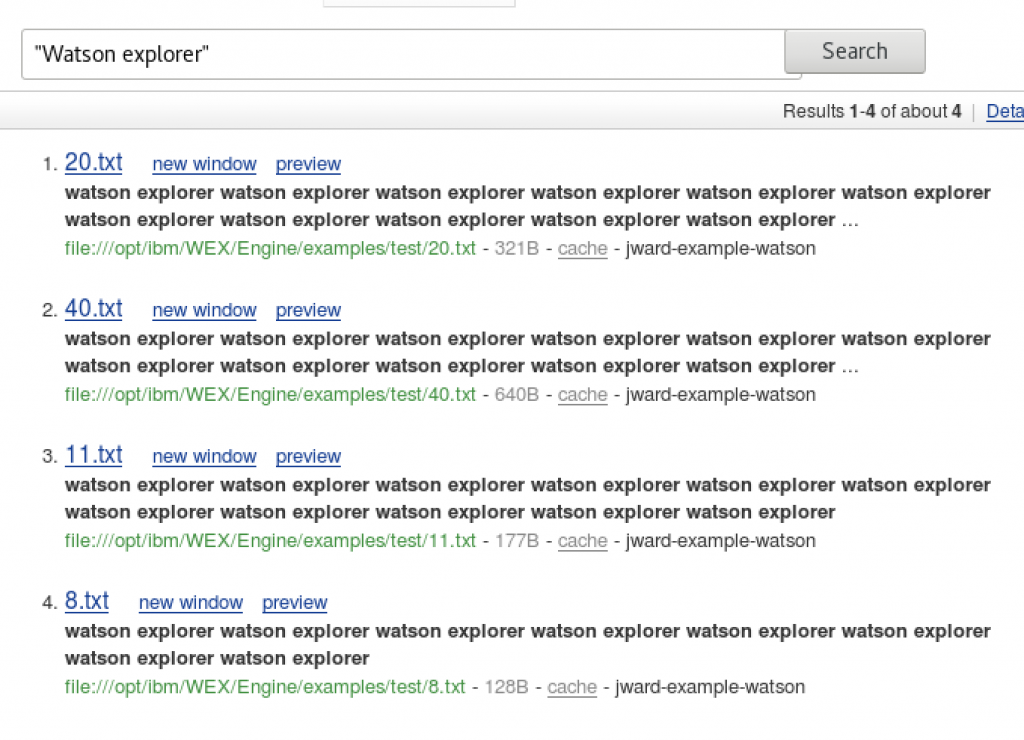
As you can see the file with “Watson explorer” 20 times is out ranking the file with it 40 times. Why is this? Well if we turn on debug mode we see that the matches are stopping after 10.
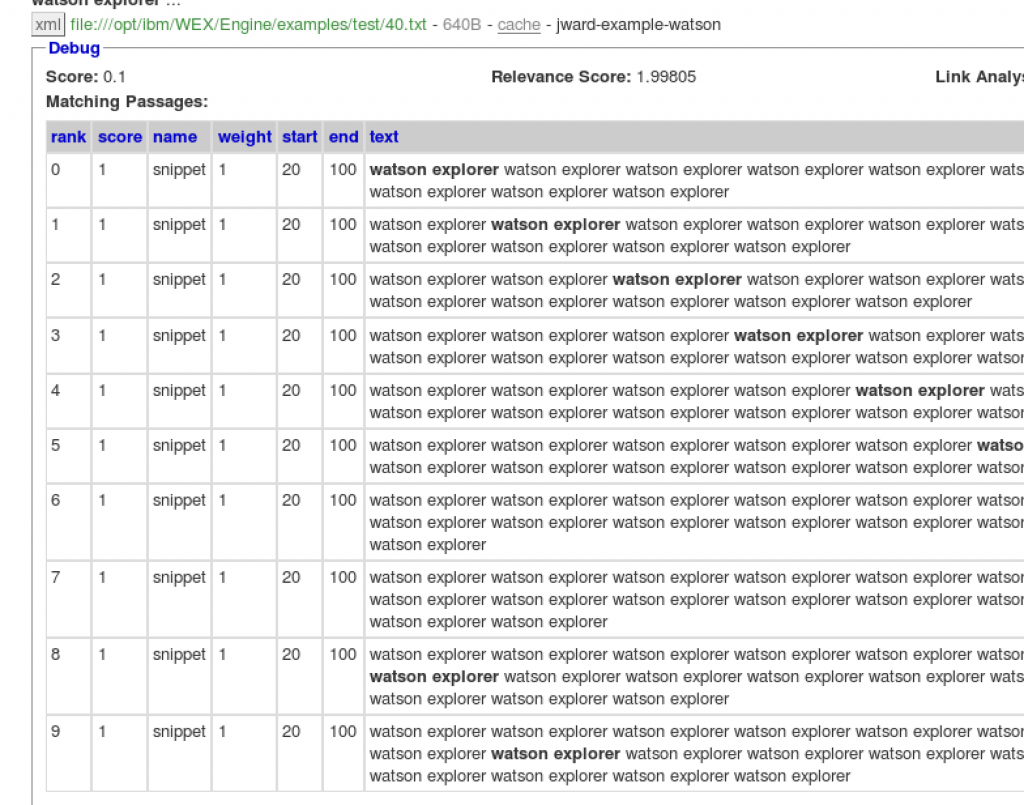
This is the same for the first 3 results. You will also notice that the relevancy score is 1.99805 for the 3 documents. The last document has a different score and is ranked correctly because it contains less than 10 matches.
So this means that WEX is only taking into consideration the first 10 instances of a match in it’s relevancy algorithm. After some digging through the configuration we found settings that limit this. On your collection go to configuration > searching > advanced and note the setting for “# ranking passages”.
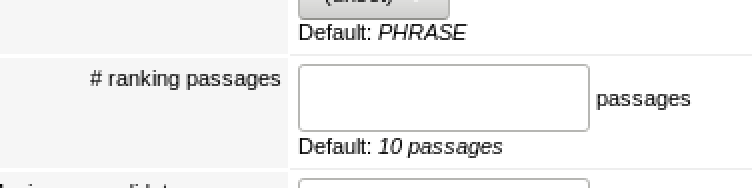
As you can see it’s set to a default of 10. This is why our debug mode matches are cut off after the 0-9. If we increase this to 50 our documents will now rank in the correct order. note: you have to update the setting then restart the indexer for your collection.
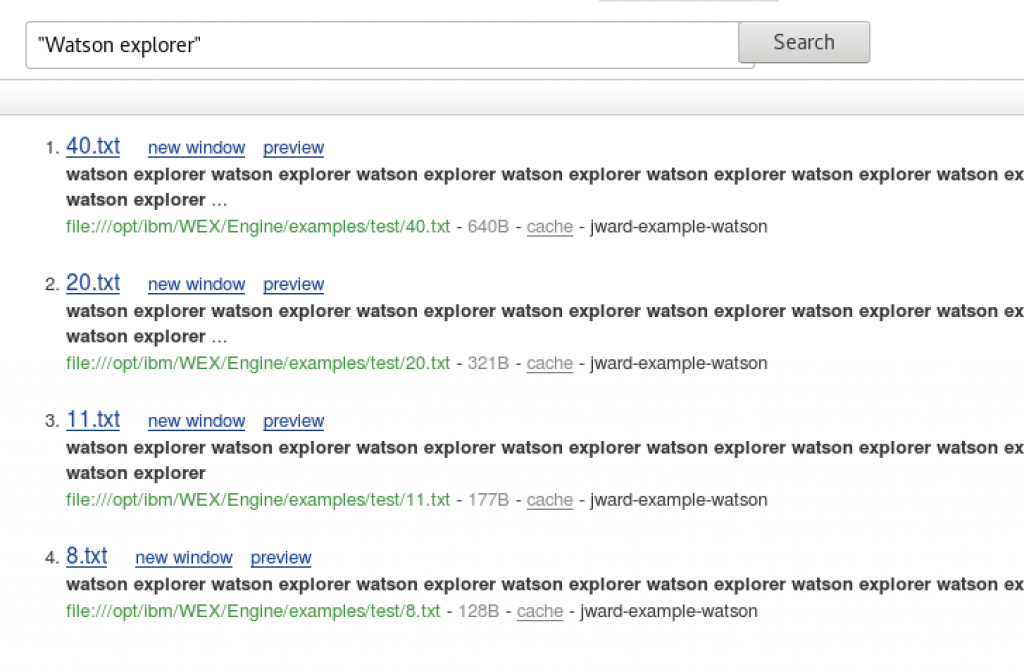
Now if I perform the same search we should see the documents listed in largest to smallest number of matches (as seen in the titles). Also if you were to turn on debug mode you would see the 40 matches in the first result.
Some things to think about. I believe IBM has set this options so low for performance reasons, but I also think that 10 is way too low for the relevancy algorithms to work properly. You want to do some testing if you increase this too much for extremely large documents with a ton of matches in them. For example, if you increase the setting to 1000 it might take a very long time to return the query results.