
I’m going to talk a little bit about IBM Watson Explorer (WEX). A few people have contacted me about what I do at my day job as a Watson Explorer Consultant. Since this is my personal site I don’t usually focus on what I do at my 9-5. I’m going to write a few posts to explain what exactly it’s like working for the IBM Watson Group and what applications I work with.
What is IBM Watson Explorer?
IBM Watson Explorer is a data discovery tool. It allows you to explore vast amounts of enterprise data. The tool allows you to consume and index data from various data sources. Out of the box Watson Explorer ships with many popular connectors for enterprise data systems. Using its own proprietary indexing technology, Watson Explorer can leverage natural language processing to deliver relevant query results to end-users. The product can also utilize Query Routing to route queries to websites and return the results within its own interface. This data can be integrated into a single, 360-degree view, application on the front-end.
IBM Watson Explorer ships with several different modules:
- IBM Watson Explorer Foundational Components
- IBM Watson Explorer Engine
- IBM Watson Explorer Results Module
- IBM Watson Explorer Application Builder
- IBM Watson Explorer Analytical Components
- IBM Watson Explorer Content Analytics Admin Console
- IBM Watson Explorer Content Analytics Miner
- IBM Watson Explorer Content Analytics Search
- IBM Watson Explorer Content Analytics Studio
IBM Watson Explorer Engine
The Watson Explorer Engine component is the key backend component of the foundational components. The foundational components come from IBM’s acquisition of a startup called Vivisimo based out of Pittsburgh, PA. Engine basically acts as an enterprise search engine that can be leveraged to crawl and indexed large amounts of data both structured and unstructured. The documents are stored as XML documents. During the crawling process, XSLT can be utilized to modify the data of the document before storing it to the index. Engine can be configured to be distributed among many servers to meet big data needs and scale quickly. The web based admin interface allows IT users a simple way to manage this powerful application. For enterprise search applications engine comes with its own search interface. To leverage 360 degree views engine must be combined with IBM Watson Explorer Application Builder.
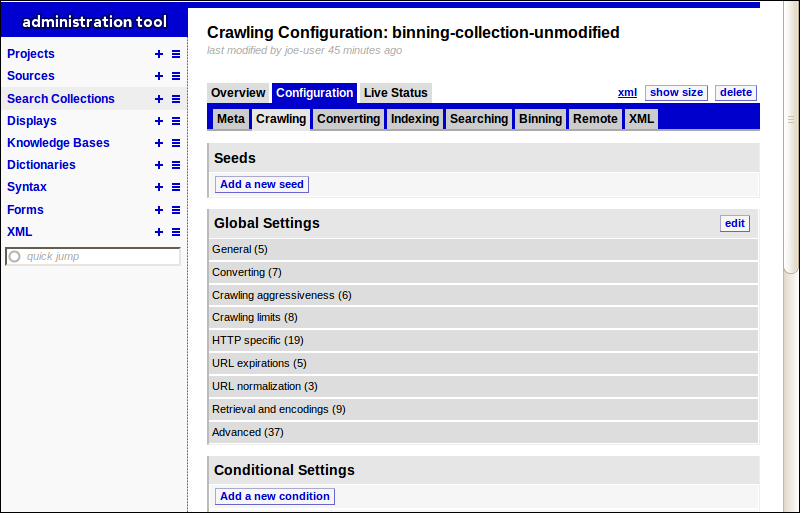
IBM Watson Explorer Results Module
The results module component allows non-technical business users to manage feature of the search results within Watson Explorer. Users can use the spotlight manager to configure spotlights that will show a boosted content above standard search results based on specific keywords. You can also use Results Module’s terminology manager to easily manage spelling suggesting, synonyms, and related terms.
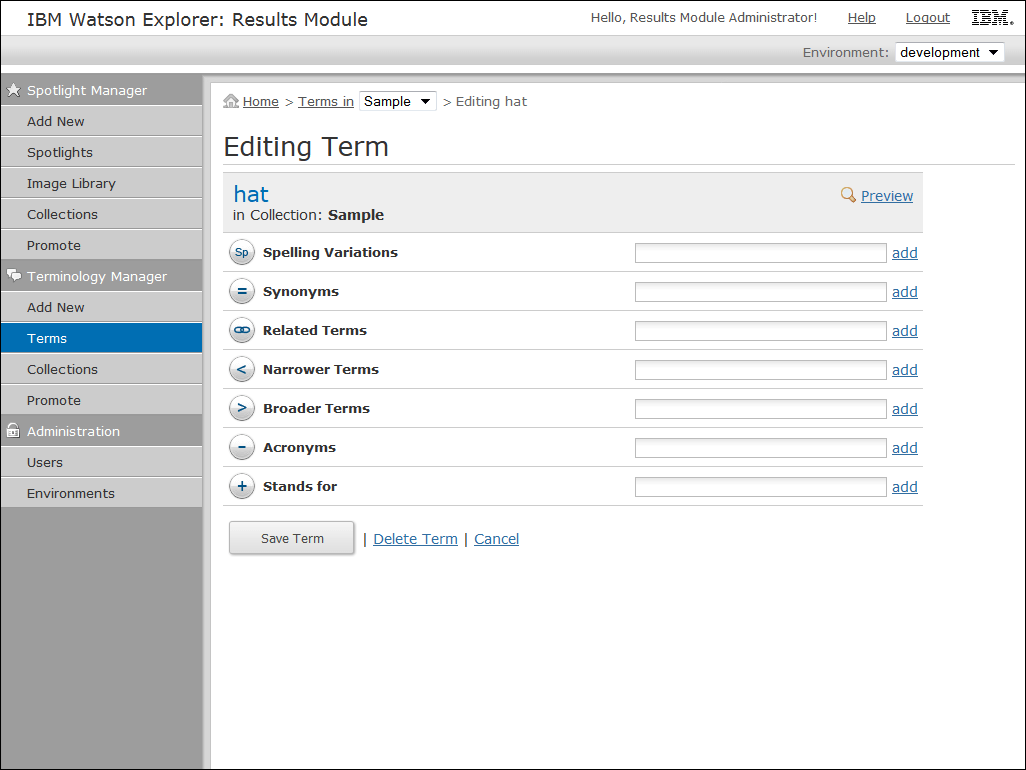
IBM Watson Explorer Application Builder
The Application Builder module is used to build 360 views of enterprise data. This applications connects to Watson Explorer Engine and displays the indexed data to the end user. One of the primary benefits of Application Builder is that you can leverage the entity model. By creating an entity for your data you can then define relationships which allows a developer to easily combine and display related data to the end user. Users can choose to follow specific entities that they are interested in. Application Builder will then provide them with the most relevant information based on what the user follows.
The technology behind Application Builder is Ruby on Rails. Specifically, App Builder uses jRuby which means that the application runs inside a JVM. So for IT purposed it can be considered as another Java application.
App Builder ships with several out of the box widgets that can be configured to display various types of data. Most deployments of Application Builder use many custom widgets. Custom widgets allow a developer to utilize Ruby (ERB), HTML, CSS and JavaScript to deliver a custom experience. This tool is very powerful and is currently being used by many enterprise customers to get the entire 360 view of their data so they can make educated business decisions.
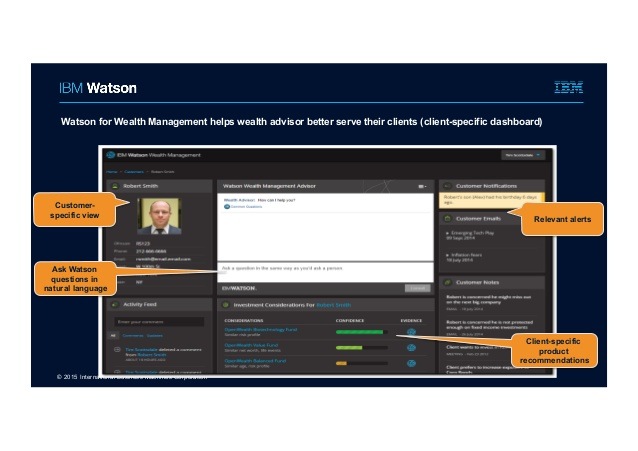
IBM Watson Content Analytics
The content analytics module is a separate piece of software from the foundational components. IBM Watson Content Analytics allows you to collect and analyze different types of content. It stores this content in its own indices which are currently separate from Watson Explorer Engine. It can consume both structured and unstructured data from documents, email, databases, websites, and other enterprise repositories. You can then perform text analytics across the data that is indexed by Watson Content Analytics.
What is a Watson Explorer Consultant
I’m a Watson Explorer Consultant. That means I work directly with customers to conceptualize and deliver Watson Explorer Solutions. My primary focus is on the Watson Explorer Engine foundational components. I use the engine, app builder, and results module components to deliver solutions to data problems at companies big and small. I’m currently one of the experts on my team for IBM Watson Explorer Application Builder. I’m able to utilize my past web development experience to deliver some highly customized solutions to customer data problems.
Our team is based out of Pittsburgh, PA but we are also distributed across the world. I currently work from my home in Ohio full time. I spend a portion of my time traveling to client sites to consult with them directly and deliver solutions in person. It takes a special kind of person to be able to handle problems with both technology and humans. If you’d like to reach out to me please use my contact form.